|
|
Minix Port Diary1/04/09Well, it's been quite a while since I gave a Minix update. First, the biggest change is that I finally got around to rewriting the boot loader such that I no longer have to boot Minix from files loaded into my old Magic-1 Monitor/OS. The new boot loader is quite a bit more flexible (it has a shell with which you can set environment variables that can be read by Minix during the boot process), and most importantly it understands my variant of the Minix FS - and will read the kernel from the target file system. I've still got some cleanup to do, but I'm pretty close to completely retiring my the original OS. I'll keep the ability to boot it up - just for old times sake. Other than that, there's just been a lot of performance tuning, and the addition of some new applications (such as an IRC client, Tom Pittman's Tiny Basic, the Small C Compiler, and probably some others I've forgotten about). I also reworked the directory structure a bit - in particular putting the games at /usr/local/bin/games. I'll probably archive this page shortly, and put any updates on the "New Stuff" page. Other than completion of the demand paging implementation (which I may, or may not, ever get around to), the Magic-1 Minix port is pretty much done. [Oh, and I also plan on posting all of the source code. I just need to review the various licenses of the code I munged to make sure I'm not stepping on anyone's toes]. 6/10/08The web server is running at an acceptable speed now (though I'd still like it to be a bit quicker). There were a number of performance issues. First, until I get the new VM rewrite completed, fork/exec will continue to be painfully slow. The standard way of handling httpd servers under Minix is to use a small utility (tcpd) which will look for incoming packets at particular ports, and then fork/exec a handler to deal with them. The fork of tcpd is a little painful, but the exec of httpd (reading the image from disk) cost a couple of seconds per session. Fortunately, the author of the code included a daemon loop which allows httpd to stay alive and simply fork copies of itself for each new session. Enabling that mode helped a bit. Second, I moved the www root into a ram disk. Third, I eliminated a reverse host lookup on incoming ip addresses. Useful for logs and debugging, but not worth the delay for Magic-1. The last was the costliest problem. The code which reads the incoming requests does so a single charactor at a time, while setting up timeout handlers in between each char. Because request headers are pretty long now and reads end up threading through several layers of the OS, this caused a multiple-second delay per request. I'm going to think about alternate ways of handling this, but for now I'm just halting the parse as soon as I see it's an HTTP_GET & URI. Now I need to rework Magic-1's web site. The old uIP one was nice in that it delivered all sorts of real-time stats about the stack and Magic-1. I'll want the same under Minix. Shouldn't be too hard - I've already added some cgi programs to do a "ps -ef" and 'finger". 6/9/08Solved the issue with the FTP (and other) hangs. Turns out it was a configuration problem. My previous setup forced a MTU of 576 bytes for the SLIP connection (on the NSLU2). The Minix networking code, however, would send bigger datagrams, and they would just get dropped before making it out onto the network. I reconfigured the NSLU2 and all is well. FTP works, as does the web server. However, the web server is incredibly slow - so slow that I think there must be some sort of timeout happening. It takes 10 or so seconds to serve a single small page. Need to investiage this further. 6/7/2008Just passed one of the last remaining hurdles for the Minix port - I've (mostly) gotten the full Minix TCP/IP stack working. Minix network support exists in the INET server, and it's a somewhat large (relatively) and complex piece of code. When I first attempted to build it last year, the code size was much bigger than would fit in a Magic-1's 64Kbyte code spaces. At the time I figured that I'd have to support code overlays to get it working. However, while getting sc to work I did another round of code generation improvements. Just for kicks, I decided to built INET again to see if it benefited from the improved code generation. As it turns out, it didn't - but this time I looked at the INET code a bit closer and realized that a big chuck of it was unnecessary. Magic-1 doesn't have native ethernet interfaces - but uses one of the serial ports with SLIP. I spent a couple of hours slicing out the ethernet-specific code in INET and found that it was within about 6K bytes of fitting. So, I dug a little deeper and found some functionality I could live without. Specifically, Minix's INET has some moderately capable routing support - which I would never use. So, I sliced that out and INET fit with room to spare. Amazingly, it also worked on first attempt (at least partially). It took a few iterations to get it configured properly to use the correct nameservers, but most everything works. I can ping out, create multiple incoming telnet sessions, finger and talk. Ftp is a bit odd - I can ftp into Magic-1, but downloading via ftp doesn't work. Also, I still get an ocassional telnet session hang. Not sure what's going on there - I probably sliced out a bit too much code somewhere. As expected, the performance is noticably slower than with Adam Dunkels' uIP TCP/IP stack that I was using. Also, the cannonical Minix web server is way too heavyweight and slow for Magic-1. I'll probably graft uIP's httpd with a low-level of the Minix stack to get Magic-1 back in the web server business. Meanwhile, though, it's looking good. It's fun to have more comprehensive network capabilities. And, at least for the time being, I've opened up some (probably unsafe) ports. You can see who is currently online by doing a: finger @magic-1.org from a Linux machine (don't know if there is a finger for Windows). Talk also works internally on my local network, but rejects conversions from the outside world. If I find a few minutes, I'll change the code to open it up to everyone. Anyway, try it out. Previously, telnet sessions were supported using a nifty gadget called a "device server". When you telnetted into Magic-1, you were really telnetting into the device server, which was hooked up to Magic-1's console serial port. Now, when you telnet in, you're coming in on the SLIP line. The console port will be attached the a real VT100 terminal that I picked up from eBay a while back. I should have the web page back online within the next wek or so. 5/26/2008Getting side-tracked on hobby projects is part of the fun, I guess. I'd intended to work on a native compiler tool chain for Magic-1, but instead spent part of Saturday porting the old "sc" spreadsheet. This is a text-mode (curses) spreadsheet originally written by James Gosling of Java fame, but heavily modified since. There is a current version you can install on Linux these days, but it is much too big to fit on Magic-1. To get it working, I had to go all the way back to a set of source files (version 2.1) posted to the Usenix group net.sources back in 1987. It was written in an ancient C dialect and took a bit of fixing up to work with my ANSII compliant lcc C compiler. I also fixed a minor bug along the way and made it work directly with the curses library instead of being hard-coded for a VT100 terminal. However, it works great - and it amuses me to no end to have a working spreadsheet on Magic-1. It's very slow, but it works. Telnet in and try "sc". I found a tutorial file from a later version that is somewhat useful. Try: sc /usr/lib/sc/tutorial.sc The arrow keys will move you around. "q" quits. Type "=" to enter a value or function. It only knows about three functions, @sum(a0:a5), @prod(a0:a5), @avg(a0:a5) [replace "a0:a5" with whatever cell range you want]. I also ran cross a nice version of yahtzee and ported it. Try "yahtzee". Anyway, lots to do at work and around the house, so I'm not sure when I'll get back to the toolchain work. We'll see.
5/19/2008It's been awhile since an update - mostly because I haven't done too much with the project lately. Over the weekend, though, I played a bit with the old Small-C Compiler. This was an early compiler for a simple subset of C which was popularized through Dr. Dobb's Journal back in the early 80's. I remembered it while reading about Steve Chamberlin's ongoing homebrew project, and thought it might be a good match for his machine. Just for kicks, I retargeted it for Magic-1. It generates pretty awful code, but I can see how to significantly improve it. That little effort has kick-started my interest in Magic-1. One of the missing pieces for Magic-1 right now is that it doesn't have a native tool chain. I have to build all of its software in a cross-development environment under Linux and then copy it over. The problem is that my C compiler, LCC, requires far more memory that Magic-1's 64K code/64K data model allows. Anyway, the Small-C compiler is now running natively on Magic-1 as "scc". It generates assembly code, and though it's a simple subset of C it is written in that subset and can compile itself. Log onto Magic-1 and try it out. There's an example file in the guest home directory: scc -t hello_world.c ...and look at the result code in hello_world.s Of course, scc is only part of what is needed for a native toolchain. I previously wrote an assembler and linker - but they also require too much memory to run natively. I've decided to write a new macro assembler for Magic-1 that will run natively, as well as a new linker. My current assembler is a quick-and-dirty affair - single pass with backpatching and no macro facility. The new one will be a two-pass assembler with support for nested include files and macros. I know how to write a macro assembler, so that shouldn't be a problem. The more challenging thing will be to write a native linker which can link targets that will use up all available code and data space. The actual symbol resolution won't be the hard part - managing the memory in a limited system will be the challenge. It's an interesting challenge though - hope to get to it soon. 1/15/2008I've been doing quite a bit of fiddling with the project lately - but not much on the Minix port. The main thing I've been doing is replacing the Ubuntu Linux box I'd been using as a SLIP bridge for Magic-1 with a very slick little gadget: a Linksys NSLU2. The NSLU2, or "slug", is sold as a cheap ($80) device to convert USB hard drives into network storage.
What I wanted to do was to get rid of an aging PC that I pretty much only used to give Magic-1 an internet connection via SLIP. It took a bit of fiddling, but it works. I reflashed my "slug" with the OpenWRT distribution, and am using a USB to RS232 serial adapter to connect to Magic-1. Via port forwarding, HTTP requests sent to my home DSL line (magic-1.org) eventually wind up at the slug, which forwards them on to Magic-1 via the serial port. In case anyone else needs to do something similar - be aware that most of the stripped-down Linux distributions for the slug were compiled with SLIP support excluded. I had to build my own kernel, as well as my own slattach. Along the way, I also ported kermit to the box - and best of all, am now using it as the cvs server for all Magic-1 source code. Oh, and I forgot to mention. All of the slug software is stored in the internal flash of the device (and I've got a 1GB USB thumb drive for cvs storage). The little box is fanless, totally quiet and draws a trivial amount of power. It comes with a standard wall wart for power, but I hacked up a cable to run it directly off of Magic-1's power supply. Here's the place to go to learn more about the NSLU2, as well as some of the other devices that have been enhanced via creative hacking: http://www.nslu2-linux.org. There is also an active Yahoo group: http://tech.groups.yahoo.com/group/nslu2-linux Finally, here links to some of the articles my brother Jim wrote about slug-hacking: http://www.nslu2-linux.org/wiki/Main/Articles In other Magic-1 news, I finally got around to adding SLIP compressed header support to my uIP TCP/IP stack. I used an early version of Van Jacobson's code as a base. It took me a while to get it working, because I missed one of the places in the code that assumed an int was 32-bits wide. Anyway, it works well now and I believe I it's noticeably faster. 12/8/2007Logic analyzers are wonderful things. Before starting this project, I'd never known how fantastically useful they can be to assist software debugging. Over the last several days, I've been tracking down a very nasty bug. Thanks to my logic analyzer, I just found it. Here's a picture of the setup:
The bug turned to be exceedingly subtle and nasty - a microcode error in the ENTER instruction that only shows up in a very unusual situation. ENTER is Magic-1's frame creation instruction. On entry to a procedure, ENTER will allocate an activation record on the stack by subtracting the size of the activation record from stack pointer (SP), and then push the previous SP. The bug showed up under the following conditions:
What happens is when ENTER attempts to push the previous SP on the frame, the store of the first byte of the PSP succeeds and SP is decremented and updated. Next, when ENTER tries to write the 2nd byte it traps with a Page Not Present page fault. The bug is that SP has already been updated following the write of the first byte. So, after the page fault handler completes, ENTER will be re-executed - but with a bad SP value. From that point on, the stack is corrupted. What made the problem so very nasty is that this situation is not only very rare, but the effect of the bug won't be felt until the called procedure tries to return. At that point control will fly off into the weeds. The only program that I have that would hit it occasionally is the web server. And, I couldn't easily reproduce it - all I knew for sure what that every now and then, the web server would hang. Luckily for me, though, the web server would tend to hang by falling into a tight infinite loop, and it stayed alive enough that I could probe its state with an interrupt handler. Here's how the logic analyzer helped. Among the capabilities of a logic analyzer is recording state traces. You connect probes to the signals you care about, as well as a clock. You can then set up conditions to tell the logic analyzer when to start and stop recording the state of those signals when the clock fires. What I did was attach state probes to the address bus, data bus, RW signal, interrupt enable signal and instruction init signal. The logic analyzer was then set to record all state and stop whenever the web server started executing in the "weeds". This would give me a trace of the instruction and data flow just before control flow went wacky. I could then examine the state trace backwards and try to figure out how we got off into the weeds. It took five or six traces for me to get enough info (and the web server would sometime run for hours before the bug was triggered). One problem was that several hundred thousand clock cycles separated the bad ENTER and the eventual flying off into the weeds and my ancient logic analyzer can store no more than 1024 states. Fortunately, you can set up the logic analyzer to only store certain states. Each failure trace gave me a little more info, and I was eventually able to find the smoking gun. This bug has been in Magic-1's microcode for years. Without a logic analyzer I doubt I ever would have found it. Tomorrow, I'll burn new microcode EPROMs and put Magic-1 back online. I still haven't found the cause of the occasional RS232 framing errors. I'll look at that next. After that - completion of the Minix demand paging implementation. Oh, and here's another picture of the logic analyzer setup:
12/2/2007I spent a little time yesterday looking at the serial port issues. First off, I cobbled together an RS232 loop-back plug. This is a device that plugs into a serial port and connects the transmit and receive lines - so that anything transmitted goes right back in. Then, I wrote some simple programs to pump data through the serial port and then receive it again and test that it was all properly received. This flushed out two software errors on my part. First, I wasn't correctly configuring the Minix serial ports, causing some handshaking errors. Next, I found that I was getting some data overrun about once every 200K chars sent/received. The latter problem turned out to be an interrupt latency issue. I had previously convinced myself that Magic-1 could respond to a hardware-handshake signal within the time it took to transmit 2 chars at 19,200 BAUD. Occasionally, though, it apparently cannot. By widening the response window from 2 chars at 19,200 to 8 chars that problem went away. I'd still like to know where that long-latency path is. When I get a chance, I should be able to find out via my logic analyzer. Meanwhile, though, I'll just keep the window at 8 chars. Unfortunately, I still haven't tracked down the sporadic framing error problem. I've eliminated a few of the easy possibilities, and currently tend to believe it may be a noise issue. I added some extra bypass capacitors to the device card, but that didn't help. A Google search turned up one schematic with a note that suggested that the Max233 chip I'm using to generate the RS232 signals is very susceptible to noise and recommended using pull-up resistors. Perhaps I'll try that. In the afternoon, though, I got a little sidetracked. My uIP-based web server has been hanging quite a lot lately and I decided to try to track the problem down. To give me some more info about where it was hanging, I added a bit of code to cause the web server to generate a stack trace upon receipt of a SIGUSR1 signal. This worked well, but showed me that whatever the problem is, it causes the web server to fly off into the weeds with a corrupted stack. So, I've got a memory corruption problem, but don't know where. I think I see a way to use the logic analyzer to help debug this. Fortunately, the hang consistently sends control to a code region that just happens to cause a tight loop. I can set up the logic analyzer to record a program counter trace and stop tracing when control flies into the bad region. The logic analyzer, however, takes up a lot of space - so I'll have to take over the kitchen table for this debugging. Monica and the girls, though, have the table pretty much locked up with Christmas decorations and craft projects. Further debugging of this problem will have to wait for a week or two. Meanwhile, I went ahead and added a very ugly kludge to the web server to keep it running. A timer goes off every 15 seconds and examines the program counter. It if happens to be in the bad region, it assumes that the web server is hung and resets it. Ugly, but that should keep things running better until I can debug further. Finally, last night I got an email from another homebrew CPU builder. Very nice project - check out: 11/22/2007Time to continue with the demand paging work - before I forget where I am. I have been doing a little fiddling with Magic-1 since VCF. Just before the show, I got ahold of an old VT-100 terminal. I'd hoped to use it at VCF, but it was acting a little flakey. It turns out that the main logic board was defective. I replaced it and added the advanced graphics option board and it works great now. There was, however, a bit of a problem. The VT-100 does not understand hardware handshaking. Flow control was done using the XON-XOFF protocol, which I hadn't implemented in my rewrite of the Minix RS232 driver (I rewrote the driver to enable use of the 16550's FIFO mode). I expected adding XON-XOFF flow control to be trivial, but I could not get it to work. I finally borrowed an ancient HP Serial Data Analyzer from work and eventually tracked the problem down to a long-standing Minix bug. The Minix TTY/RS232 code that examines the termios structure to look for the flag that enables XON/XOFF flow control was looking at the wrong field. It was likely just a typo - the code was looking for the IXON flag in the "c_lflag" field rather than the "c_iflag" field. Once that was fixed, the old VT-100 was up and running all the way to 19200 BAUD. That led me to my current problem. While I was messing around with the serial ports, I decided to look a little closer at the throughput of my web server (which uses SLIP to connect to the internet via Magic-1's auxiliary serial port). I've noticed some strange behavior. It is sometimes much slower than I think it should be, and it also get quite a few packet checksum errors. To make a long story shorter, it turns out that I am getting a significant number of framing errors on the auxiliary serial port. I'm pretty confident that my sending and receiving baud rates within spec, and I've also noticed that the framing errors seem to only show up at the beginning of a packet transmission. I ran several hours of a ping flood without getting any framing errors. However, with sporadic TCP/IP packets I can usually get one every couple of minutes. There are quite a lot of things I can do the track this down further. I don't yet know whether I have the same issue on serial port 0, or even if the framing errors are showing up on the sending side (i.e. - the Linux box on the other end of the SLIP connection). Some things to look at:
Once I get this problem tracked down, I'll revising demand paging. And after that works, I think I'll be done with the project. 10/30/2007I think I've run out of time. Demand paging is partially working, but looking ahead at the week it's clear that I won't have enough time to fully debug it by Saturday morning. I've decided to revert to an pre-paging version of Minix for VCF. I'll need what time I can find between now and Saturday to clean the system up and get it ready for the show. My plan is to have it running with a pair of terminals to show off the multi-user aspect of the Minix port. I've got a VT100, but unfortunately it is acting flakey at the moment. I'll probably end up using a borrowed Data General Dasher terminal and Ken Sumrall's old HP terminal. I did some testing this evening with the Data General Dasher. I don't have the termcap entries quite right, but it mostly works. It's kind of fun to see timesharing in action. I was running the old "worms" curses program that causes some text-mode worms (or snakes) to randomly wiggle across the screen. With two sessions running at once (one on the DG and one via Kermit on my laptop), you clearly see the worms alternately move from one session to the next. And, or course, lots of blinky lights. 10/28/2007I probably only need a few evenings to complete the demand paging implementation, but I'm not sure I'm going to find the time between now and this weekend's VCF. I may need to roll back to a previous version of my Minix port, as the current state is very slow (now that I've ripped out the 2nd-level block cache and eliminated read-ahead). I'll see what I can be done by Wednesday and make the call then. For the time being, I'll continue to keep the machine off-line. 10/22/2007Another busy weekend, but I was able to find a few hours to work on the demand paging implementation. Mostly I worked in FS, the File System server. I've removed the 2nd-level disk block cache, as well as the code to opportunistically request read-ahead. This slows the system down even further, but I expect to make it up (and more) during the next stage when I implement a much more capable page caching mechanism. My intent is to replace the explicit disk reads in FS with the equivalent of mmap(). Essentially, when the file system wants to read a disk block on behalf of a user read() system call, it will simply register a mapping between that block and a portion of its virtual address space. Then, we can just copy from that virtual space to the user's buffer. On the first access, we'll get a page fault, which will be handled by the paging mechanism to either read the block in from disk, or just update FS's page table with a previuosly cached page containing that block. So far, I've dummied up the old get_block() to send a message to the PAGER to fault in a page rather than send a message to the block device driver to read the page. Next up - adding a hash table lookup to MAPPER to store device/block pairs to physical pages. 10/15/2007OK - things are looking better now. The problem I was having in getting the page fault control flow working turned out to be a spurious use of one of the special instructions I added to Magic-1 (that now look pretty useless). When designing Magic-1's instruction set architecture, I had Minix in mind. One of my concerns was the cost of message passing, so I created a couple of instructions that would quickly copy between kernel memory and user memory. The way they worked is that either the source or destination pointer would be translated using the current user-mode page table whiel the other address would use the kernel page table. It seemed like a good idea at the time, but the problem is that I can't really do any cross-process copy in kernel mode without first verifying that the source & target pages are present and have the correct access permissions. Otherwise, we take a page fault - which is generally a bad thing to do in kernel mode. I think I'm going to have to replace all uses of TOSYS and FROMSYS with the much more expensive vir2vir_copy() calls. The latter will validate the source and/or target locations as needed before attempting the copy and will pre-emptively handle potential page faults. Anyway, it now looks like the basic mechanism is in place. Normal user-mode page faults go through the trap handling system, which will block the faulting process and send a message to the PAGER task to service the fault. For all system calls done on behalf of a user process, the kernel tasks will always perform a "validate_pagerange()" call prior to reading or writing user memory. If a potential page fault is discovered, validate_pagerange() will attempt to fix the problem by passing a similar pagefault message to the PAGER task. Note that the calling kernel task will be blocked until the fault is handled. 10/14/2007Each October, the town I live in (Half Moon Bay, CA) holds something called the "Pumpkin Festival". It has become somewhat popular, and the result is that so many people come to town folks who live here generally just try to stay at home to avoid the traffic. This weekend was Pumpkin Festival, and staying at home is mostly what I did. As a result, I was able to spend some time on the project. I worked on the control plumbing for handling page faults, and part of it seems to work well. If a user-mode process takes a page fault, the fault handler constructs a message for the PAGER task and removes the faulting process from the ready list. The PAGER task will eventually run, handle the page fault and then make the user process runable. I tested this by allocating memory as usual, but turning off the page present and page writable bits in the process's page table. The user process would fault on first access, and PAGER would "handle" the fault by simple turning the present and writeable bits back on. It all worked just fine. The part that doesn't work is taking a similar action whenever another kernel task needs to fault in pages on behalf of the user process for which it is performing a system call. My (probably faulty) understanding of the message passing mechanism is likely the problem here. For things to work as I envisioned, some kernel tasks would need to send a message to PAGER and then block awaiting a reply. I thought a simple send(PAGER,&msg), recieve(PAGER,&msg) pair would do the trick, but Magic-1 tends to fly off into the weeds after a few of these. To simplify matters, i tried doing a similar send/recieve from the SYSTEM task to PAGER with a null request - and it failed as well. I think I need to review the message passing mechanism in a little more detail. 10/9/2007The file system has been rebuilt, and Magic-1 is back on-line. I've re-enabled the guest account: user: guest pasword: magic Telnet to magic-1.org and check it out. Lots of applications to run at /bin, /usr/bin and /usr/local/bin 10/8/2007OK - found a bit of time over the weekend and rolled my Minix port to using a file system with 2K blocks (rather than the stock 1K block size). Now I'm in the process of re-bootstrapping my disk image - which is a bit of a pain. I still don't have a very good way of moving files directly between my Linux development environment and Magic-1's Minix file system, so for the moment I'm still using a simple utility on the old Magic-1 Monitor/OS which knows a little about the Minix FS. Anyway, it will probably be a day or two before it's completely rebuild and I can put the machine back online. I'm hoping the next couple of weeks won't be quite as busy as the last two have been. I'd like to complete the demand paging implementation in time for VCF 10. 9/30/2007Still very busy on the home/work front, so not much progress. I did, however, decide to go ahead and do a more complete implementation of mmap() and munmap(). I had originally planned on just doing enough to support demand paging of application code & data - which would not have requried me to keep track of modified pages or write them back to the disk file. It is considerably more complex to do read/write mmap() support, but I find it an interesting topic. One of the main differences is that I'll have to retain much more complete data on which pages are mapped by which processes. I'm also planning on integrating a much larger disk block cache mechanism into PAGER. Minix currently has a small disk caching mechanism in FS, but Magic-1's 16-bit address space make it not especially useful. What I have in mind will open up all unused RAM pages for disk cache. The other planned change is to rework the file system to use 2K blocks, rather than stock Minix 1K blocks. Making the disk block size the same as my memory page size will make life much simpler. I could have gotten away with a size mismatch when I was just going to support execution demand paging, but full mmap() support will be much simplified when page size and block size are the same. The unfortunate aspect of this is that I will have to completely re-bootstrap my file system. I expect to continue to have little to no free time over the next week, but things should ease up a bit after that. I hope to get all of these changes done by the end of October so I can demonstrate Magic-1 running a fully multi-user, multi-tasking, demand-paged Minix 2.0 at VCF 10 (which will be held Nov. 3-4 at the Computer History Museum in Mountain View, CA. 9/22/2007Given that I'm probably going to have to put further implementation on the back burner for the next week or so, I've decided to do a brain dump of my current thoughts for the implementation of copy-on-write and demand paging. It will evolve as my thoughts evolve. Here it is: Minix Demand Paging Design 9/21/2007Time for another update: extremely busy at work (and home) lately, so I haven't done much coding on the demand paging enhancement (but have been doing a lot of thinking...). A week or so ago I did go ahead and eliminate phys_copy() from the kernel. In its place I now have four memory copying routines: vir2vir_copy(), vir2phys_copy(), phys2vir_copy() and phys2phys_copy(). Additionally, the old kernel routines that converted from virtual to physical addresses, umap() and numap() have been replaced with validate_pages(). This new routine is intended to verify that a virtual address range is resident before a kernel task attempts to access it. It will force page faults prior, if applicable, and is generally called from within the above copy routines which take virtual address sources or targets. I'm generally pleased with the new copy routines. They actually speed things up a bit, but more than that make the code more explicit about what is going on (as well support non-contiguous physical <=> virtual mappings). I expect the paying job to keep me pretty busy for the next couple of weeks, so I probably won't be making too much progress on fleshing out demand paging. Meanwhile, if anyone would like to check out the current state of the port I've enabled an open guest account. Telnet to www.magic-1.org, and use: user: guest password: magic Note that there isn't a native C compiler, so you won't be able to build new applications. To see what applications are available, check out /usr/bin and /usr/local/bin. Do keep in mind that it's a very slow system by today's standards (though I hope to make it seem much more responsive when I get demand paging working). Over the last several years I've gotten quite a few emails from folks who say that'd really like to build a system like Magic-1, but can't because they don't know how. I'm afraid they're missing the point. If I had known how to do it, I wouldn't have bothered. It was interesting to me *because* I didn't know how to do it. With that in mind, I'll have to say that adding demand paging to Minix is an especially interesting task. And, I think I'm getting a pretty good handle on how I'm going to do it. More on that later. 9/10/2007The next stage of the implementation of demand paging is going to mostly be thinking about it. I've looked through the source code a bit, and did a simple implementation of the new fmap() system call (which, given a file descriptor and a memory range, returns the device and list of raw blocks that represent the range). I expect that at the end of the day, I will end up adding a very small amount of code to get this working. Most of my hobby project time over the next few days or weeks will involve thinking through what that small amount of code should be. The first problem is how best to break Minix's underlying assumption that the physical memory that is associated with virtual memory spaces is contiguous. A key kernel routine is phys_copy( phys_addr, phys_addr, length), which copies data from one place in physical memory to another. The problem here is that this routine is incorrectly used throughout the kernel to copy virtual memory ranges to either physical memory or another virtual memory range. For example, if a process wants to write a buffer full of data to a disk, it will call the write() system call. That system call will eventually need to copy that data to kernel memory and then copy push it through the disk interface hardware. When the process makes the write() system call, it passes it's notion of the buffer's address - which in reality is a virtual address specific to that process. The kernel will then convert that virtual address to a physical address, which it then passes to phys_copy() to copy the buffer's contents to kernel memory in order to process it. Here's the problem in a nutshell: In a paged memory architecture like Magic-1, a process's memory consists of a series of physical memory pages along with some address translation hardware to convert the process's virtual addresses to the actual physical addresses of the underlying physical memory. The actual addresses of the physical pages need have no ordering relationship relative to the virtual pages. So, address 0x17ff in virtual space might map to physical memory address 0x337ff in physical memory and the following byte in virtual space, 0x1800 could map to physical memory 0x10800. Minix's phys_copy() routine is fine if you are really wanting to copy physical memory, but it should not be used to copy virtual memory ranges which might possibly cross a page boundary. It works only because existing Minix implementions require contiguous virtual memory ranges to be associated with contiguous physical memory ranges. There are a couple of approaches I could use, and I'm not sure yet which one I'll use. First, I could preserve the way Minix uses phys_copy() by redefining what a 'phys_addr' is. In all existing Minix implementations (at least that I know of), a phys_addr is defined as an unsigned long, or some other integer-type that is sufficiently large to address all possible physical memory. I could, I suppose, redefine it for Magic-1 to be a struct/union which could either be a true physical address, or a [process/virtual address] pair. Phys_copy would then be changed such that it would redo the virtual<=>physical address mapping any time either source or target pointer crossed a page boundary. That would likely allow the least perturbation of the source code, but it feels a bit ugly to me because it continues to use phys_copy() in a way I think is wrong. The other possibility is to add a few more xxx_copy() routines which are explicit about what they are trying to do: virtual_to_virtual_copy, virtual_to_physical_copy, physical_to_virtual_copy, etc. This would involve a bit more work, but I think it would also make the code a little more understandable by explicitly making clear the intent of the action. Anyway, some things to think about. 9/9/2007Spent a few hours on the project today in between dropping the kids off at various activities. A good chunk of the infrastructure for demand paging is now in place. I've added a MAPPER task, which runs in user space like FS and MM, but is given kernel task priority. I've put three system call placeholders: mmap, munmap and fmap. The latter system call lives in the FS server and given a file descriptor, starting offset and length will return a vector of block addresses on the drive deive. I've also implemented that system call, which simply amounted to adding a loop wrapper around an existing routine which would take a file pointer and offest and return the physical block number that it represents. This continues to look like the addition of at least my minimal demand paging on Minix wil turn out to be almost trivial. The ony substantive issue (at least that I know of now) is working out he details of having the system task directly invoke the appropriate block device driver to service the fault (using the mapping info ). This would be easy if I enforced a busy-wait mechanims for fetcing disk blocks, II also need to spend a little time thinkging abut the implecations (and likely necessity) of maintaing reference counts on the disk lblocks. Also, I've had the beginnings of an idea about how to all "unused" physical pages as a victim cache pool. 9/8/2007I'm starting to think a bit about adding demand paging to my Minix port. I'm still in the early, fuzzy thoughts stage - but find it useful to write down what I'm thinking. So, most all of this is likely to be badly wrong, but here goes: First, demand paging is generally used in situations in which you have a larger virtual address space then your physical memory. This is not the situation for Magic-1. I actually have plenty of physical memory (4MB), but tiny per-process virtual address spaces (64K code and 64K data). So, my intent is not to use paging to support applications whose virtual address needs exceed physical memory, but rather to do "lazy" fetching of code and data from disk. The primary goal is to improve the perceived responsiveness of the overall system by only fetching from disk the portions of applications which are needed. (Note: my IDE hard drive interface is extremely slow - I haven't measured it recently, but I think that my top transfer speed is in the vicinity of 20K bytes per second). A significant implication of this is that I can essentially ignore what is generally a big part of demand paging - swapping and page replacement mechanisms. Once I page in some data, it can stay resident until the process dies. I'll design things in such a way that swapping and page replacement could be added later - but it isn't something I'll ever likely need. If it do it, it would just be as an exercise. To implement demand paging, I'll need to add two new system calls: mmap() and munmap(). These syscalls associate a virtual address range with a file. There are a lot of possible features and options that other Unix-like implementations have added to mmap(), but at least at first I will only need a tiny subset. To meet the immediate goals, I need only support READ, EXECUTE and PRIVATE fixed-address range mappings. Looking only at the simple cases first, I could see supporting these syscalls in the MM (memory manager) server. This is where fork and exec happen. The main change would be in do_exec(), which currently calls out to the FS (file server) to open an executable, read the header and then read in the code/data and finally close the file. I think the general idea would be that do_exec() would open the file as usual, but not read in the code/data - and further, not close the file. It would keep it open and associate the fd with the process. It would allocate a page table with all entries unmapped, but tagged as file-backed. When the applcation is launched, it would take a page fault, sending control to the kernel. The kernel has a copy of the page tables, and after verfifying that the page fault was recoverable, it would contruct a message to send to MM to service the fault. MM would then allocate a fresh page and either copy from an existing page (if it was a copy-on-write page fault) or invoke the FS to fill the page from the backing file on disk. Once all that completed, the process would be made ready to run and re-attempt the instruction which caused the fault. Now, if this was all there was to the problem, it would be quite simple. What I've described above could be done with a negligable amount of new code as most of what is needed already exists in Minix. The difficult part - at least I'm having difficulty wrapping my head around it, is what to do if the page fault happens not during normal execution, but as part of a system call made on behalf of the application. For example, suppose a program does a file read, and requests that the newly-read data be placed in a buffer that has not yet been mapped. If we didn't know ahead of time that the user buffer was unmapped, we'd face the situtation that the FS would take a page fault in the middle of an operation and then need to be invoked itself to service that fault before it could continue. Minix's single-threaded design makes this difficult. There are other similar issues, but they generally boil down to how to handle or avoid a page fault when doing a system call or other OS-level operation. At the moment, I'm thinking in terms of validating system call arguments on entry to the MM and FS, with the intent of making sure the pages are in place before proceeding. However, this gets a bit ugly as only the kernel and MM have copies of the page mappings. I really don't like the idea of having all servers get a copy of the mapping, but the overhead additional message passing to MM to verify seems way too much. Alternately, I suppose we could take another approach where we just run as if things are good, take the fault and then somehow back up and restart the system call after the page fault has been dealt with. Not sure what to do here yet. Need to think on it a bit. [Update] - I think I'm seeing the beginning of a solution to this problem. The key problem is at the time of page fault, we would need to invoke MM to allocate a page of physical memory, and then FS to locate and read the physical sectors on the disk the page is to be loaded from, but page faults could originate on behalf on MM and FS - which are not re-entrant. One thing I hadn't mentioned above is that because MM and FS are user-mode processes, they would never actually generate a real page fault on behalf of a client. Instead, they call back into the kernel's SYSTEM task to perform memory copies to and from client processes memory. The SYSTEM task uses umap() to identify the target user memory pages and knows whether the target pages are mapped. So, SYSTEM would be in a position to "service" the fault before it happened. That, however, still leaves the problem of having to re-enter MM and FS to allocate a memory page and locate the bits to be faulted in from the block device. But what if we did not have to re-enter MM and FS? In other words, what if the ability to allocate a physical page of memory and the knowledge of the mapping between an unmapped virtual memory page and its disk-backed storage were available outside of MM and FS? Assume we have a new server called MAPPER. This server could be viewed as a data repository which never initiates requests to other tasks or servers, and thus would avoid participating in a possible deadlock situation. It would have two jobs:
On startup, MM would hand off the MAPPER a list of all free pages. At the time of a fork(), MM would no longer allocate physical pages to a child, but would simply copy the parent's page table and ask the SYSTEM task to mark both the parent and child's data page as read-only (i.e. - copy-on-write initialization). For an exec(), MM would not allocate physical memory pages, but simply initialize an unmapped page table. As before, it would call FS to read the new program's header to determine code, data and bss sizes, but instead of actually reading the code and data into physical memory, it would ask FS to return mapping structures which identify which disk blocks (or sectors) are backing the unmapped virtual pages. MM would then pass this structure off to MAPPER. When a process takes a recoverable page fault during normal execution, the kernel would construct a message describing the fault and sent it to the SYSTEM task. SYSTEM would ask MAPPER to allocate a fresh physical memory page and also return the device/block/sector info describing where the needed bits live. SYSTEM would updage the process' page table with the new physical page info. Finally, the appropriate bits would be copied to the new page either directly by SYSTEM if this was a copy-on-write fault, or by sending a read message to the appropriate device driver task. Once the fault was serviced, the faulting process would be made runnable. The above actions would also be taken by the SYSTEM task if it detected an impending page fault that would be caused by a SYS_COPY request made by the MM or FS servers prior to performing the SYS_COPY (it would discover this during the execution of the umap() call that happens prior to phys_copy()). This appears to solve the re-entrancy problem, as neither MM nor FS would need to be invoked to service the fault. And, at least right know, I don't see any deadlock possibilities. Other details and questions include:
I'll think about this more over the weekend, but implementing demand paging for Magic-1 Minix could turn out to be quite simple. 9/7/2007Last night I added the vfork() system call to my Minix port in hopes of speeding up fork/exec. It works and is measurably faster - but not noticiably faster. I had hoped it would improve the apparent responsiveness of the system. I guess the next step is to go ahead and implement demand paging - which is likely to be a significant bit of work. In my previous Monitor/OS I implemented a simple form of demand paging and it made a noticable difference in the percieved speed of program launch. In short, demand paging works by loading just the portions of the program that are needed as the program runs. Currently in Minix, if you exec() a program all of the code and data is loaded from disk before any execution begins. For Magic-1 and a typical program, this can take up to 4 or 5 seconds if the program is on the hard drive (or a second or two if it's on the RAM disk or in the 2nd-level RAM disk cache). With demand paging, you can start getting output much quicker because only a small portion of the program typically needs to load before a prompt of some sort is display. In some cases, demand paging can reduce overall performance (because if you really need to load everything it is more efficient to do it all at once), but is can make the program "feel" much more responsive - and that's Magic-1's biggest issue right now. I have some ideas about how to proceed, but the first step in any case is to rework Minix to allow programs to have non-contiguous code and data physical memory. I can go ahead and do that while working out the details of the paging support (which will likely take the form of a new PAGER kernel task). The tricky part will be handling (or avoiding) page faults on behalf on user processes that would occur during the execution of system calls by that process. 9/2/2007Lots of good progress over the holiday weekend. I completed the instruction set changes along with some LCC tuning and saw dramatic improvements in 32-bit arithmetic (as well as large memory copies). The new instructions are:
Now, vi and awk fit in my 64K code space - and both work great (although I did have to find and fix a subtle bug in my a.out.h header file that was breaking any program that had code on the final page of code space). This should be about the end of any microcode or instruction set changes. I've only got a tiny amount of free microcode space and had to carefully examine and rework a lot of the existing microcode to make space these instructions. I had hoped that I might also be able to get the last of the 16-bit Minix programs to work - INET, the TCP/IP server. However, it's just a bit to big (about 15K bytes over). Whereas the problem with the other programs was the (now fixed) advantage x86 had over Magic-1 due to memory-to-memory operations, the issue in INET is that Magic-1's runtime calling convention is a bit more verbose that that used by the x86 Minix compiler. And, INET does a lot of small procedure calls. The x86 Minix convention pushes args on the stack, and can do this in just a few instrucion bytes. Magic-1 uses a fixed frame convention and generally has to to a load/store pair to pass an argument. I don't see an easy fix for this, so I'll likely have to either implement code overlays or remove some of the INET functionality. I'm very happy with my new 4-byte memory copy instruction. Stock Minix doesn't support paging, and ends up doing a lot of memory copying. I wrote a kernel-only memcpy() routine that includes a massively unrolled loop of memcopy4's that nearly triples the speed of page (2K) and file system block (1K) copies. The improvement is noticeable. The system is almost usable now, and once I do something about the poor fork/exec performance it should give a reasonable responsiveness (considering the 4.09 Mhz clock speed). Here's a partial list of things I need to do:
I expect that I'll be ready soon to open up a general guest account for folks to try the system out. 8/26/2007One of the great things about building your own machine is that you can do whatever you want. I'd gotten used to big-endian bit and byte ordering from my days working on HP's PA-RISC machines, so it seemed natural to make Magic-1 a big-endian box. I also did it because it was a bit contrary to the rest of the world these days. On Magic-1, the most significant bit in a byte, word or long is numbered bit 0, and 16-bit integers are stored with the most significant byte at the lower address. I kept up this convention when doing code generation for 32-bit integers. A 32-bit integer 0x12345678 would be stored with 0x12 in the first byte, 0x34 in the second, 0x56 in the third and 0x78 in the fourth. It seemed the consistent and right thing to do. However, I wasn't thinking clearly when I designed my latest batch of instructions to support 32-bit moves and 32-bit arithmetic. The specifications, and microcode, correctly deal with big-endian ordering within a 16-bit integer, but treat the two 16-bit words that make up a 32-bit long in little endian, rather than big endian order. I specified the instructions as using post increment: add.16 (a++),(b++) with the intention that I could support multiple precision integers by simply doing a series of these operations in line. See the problem? We have to do arithmetic starting with the least significant words - which in a big endian world come after. So instead, I need to make my new instructions pre-decrement: add.16 (--a),(--b) For example, if we have the following C code: long foo; The code I need to generate would be something like this: lea a,foo+4(dp) In other words, we need to point just past our operands, and then walk from least to most significant using pre-decrement rather than post-increment. Similarly, I had designed the new 4-byte memcopy instruction to not alter its base pointers. The idea was that for a 3-operand operation, I could avoid one of the leas. Instead, I'll need to have the memcopy update its base pointers as well. This will also be useful for general memory copies, but will be a bit of a challenge to code (again, the issue with not committing changes until we're sure we're not going to fault). The following code long foo; would be generated as: lea a,foobar(dp) I haven't yet reworked the microcode to see what changing from post-increment to pre-decrement will do. I'm guessing it won't hurt the arithmetic instructions, but it probably will cause my 4-byte moves to slow down a cycle or two. [update] - Okay, I looked at the microcode. The arithmetic operations can be trivially changed from post-increment to pre-decrement without cost. However, adding post-increment to the memcopy4 will be costly. One problem is that I don't have an easy way of generating a "4" in microcode. My microcode definition includes the ability generate constant 1,0,-1 and -2, and to get a 4 I would have to burn two clock ticks to add 1+1=2, and then 2+2=4. It looks like it would cost 4 additional clock ticks. This is too much - moving a 4-byte copy from 13 to 17 clock cycles. Much of the time I won't need the auto-increment, so those 4 cycles would just be wasted. I guess I'll just use lea to adjust when necessary. 8/24/2007Time for an update. I've given quite a bit more thought to my 32-bit code generation issues. First, I took a close look at the performance and code-size consequences of moving 32-bit mem copy, addition, subtraction, and & or from my current in-line sequences to fast runtime "millicode" calls. The good news was that doing this would largely solve my code size problem (both vi and awk would fit in a 64Kbyte code space without having to resort to overlays). The bad news is that it would go a lot slower. So, I decided to try to figure out any instruction set changes that could help. As far as ISA differences between Magic-1 and X86 go, it is really the memory-to-memory operations that gave x86 the edge in code size when doing a lot of 32-bit integer math. I've avoided doing memory-to-memory ops for Magic-1 for several reasons. The most important is that it's kind of tricky to get right. The main issue is how to handle instruction rollback in the event of a page fault part-way through an operation. For example, suppose you have a 16-bit memory to memory add instruction, where *op1 += *op2. Suppose also that op1 is located in memory at such that one byte of it falls on one page, and the other on the next page. With a machine with an 8-bit data bus (like Magic-1), you need to do this operation a byte at a time. If the first byte from each operand is on a page that is resident, you can load add and store them. However, if you take a page fault while loading the second byte, you cannot roll the instruction back to retry it later (after the page is faulted in), because you've already stored the first byte. This is less of an issue for a memory copy, because at worst you will redundantly copy the first byte after a restart, but when you're doing a 2-operand addition, you've trashed your first operand. Most modern CPU's either disallow page-crossing (requiring 4-byte int alignment) or have a probe mechanism to test whether a fault would happen before committing a change. I considered adding a probe facility, but decided that the cost would be too high (a decision I now question, after working with some of the Minix code). Anyway, I'll cut this short. I bit the bullet and designed a new set of 16-bit memory to memory arithmetic operations: add.16 (a++),(b++), adc.16 (a++),(b++), and.16 (a++),(b++), or.16 (a++),(b++) & xor.16 (a++),(b++). These are all 1-byte opcodes, and will not only enable me to keep 32-bit arithmetic inline, but will do it in fewer bytes than an millicode call and significantly faster than even the old in-line version. The instructions will treat the first operand, pointed to by the address in register A, as both the first source operand and the target. Additionally, they will auto-increment the two pointers to allow multi-precision arithmetic. For example, a 32-bit addition of two frame locals would look like:
In most cases, this will require only 6 bytes of instructions and 36 clock ticks, vs 19 bytes and 44 clock ticks for the current code. This is a big win. To make this work and allow instruction restart, however, I've had to get a little unclean. I wrote the microcode in such a way that the first byte of the result is not stored until we're sure that there will be no page fault. So, the instruction starts off by loading operand 1 and then immediately storing it back. If we survive this, we know that the page[s] are both readable and writeable. Next, operand 2 is loaded. Once this is done, we're golden and can therefore commit changes to memory and registers. Note that this means these instructions should never be used to access I/O devices, which often have side effects on loads and stores. There is one additional pretty ugly hack. All of these instruction will destroy the contents of register C. I simply needed more temp storage to hold on to operand 1 until it's safe to commit. Normally, this isn't too bad - register C is also modified in the counted instructions (memcopy, strcopy, vshl, vshr). However, the gross hack part is that C is not rolled back in the event of a page fault part-way in. This is not very clean, but the performance payoff here seems to justify it. We'll just document it and call it a feature. This is a large change. I had a few free instructions that I was saving for FORTH opcodes - but not enough to add all of these new ops. So, I've had to remove several instructions from the ISA, and rearrange others. This means that once I update the microcode, all previously compiled Magic-1 code (on disk or in ROM) will be broken. I plan on making this change in very small steps over the next week or so. After these changes are made, the only bit of Minix that still has a code expansion problem will be INET, the TCP/IP stack. I'll examine that in detail later - perhaps I can completely avoid having to write an overlay mechanism. 8/20/2007I decided it was time that Magic-1 started serving web pages again, so I recompiled my uIP web server. I had to fiddle a bit with non-blocking I/O, but it seems to work. The performance is about 15-20% slower than what I was getting with my old Monitor/OS. I hope to close the gap a bit with tuning, but am unlikely to reach the same performance level (my old OS didn't do nearly as much, and was highly tuned for uIP). Anyway, it's back serving web pages now, as well as periodically sync'ng Magic-1's real-time clock with a network time server. One other thing I need to do is change the appearance of the web page to highlight the fact that it's now running Minix. The old site had a feature that would load current stats about the OS (last visitor's comment, number of commands executed, etc.). I think it would be nice to do this for Minix as well - something like push a button and do a remote "ps -ef" or "who". In other news, I've been looking more closely at my 32-bit code generation (which is much, much worse than the x86 Minix code). The big problem is code expansion, which largely caused by the following factors:
Some of this I can fix with a peephole optimization pass, but the biggest bang for the buck will come from supporting 32-bit operations out-of-line and by adding some new instructions. The first two instructions are short-form "lea [a/b],#u8(sp)" ops. These generate an SP-relative address, but take a 8-bit offset rather than a 16-bit one. The vast majority of current SP-relative leas will fit in 8-bits, so this will save a lot. Next, I'll add a special-purpose 4-byte memcopy instruction. Not only will it reduce the code size of a 32-bit copy from 8 bytes down to 5 (lea, lea, memcopy4), but it will do the copy in 18 clock ticks rather than the current 28. 8/16/2007I'm a little less confident that I've got the new serial port driver correct. I've been trying to get Adam Dunkels' uIP TCP/IP stack running and am having some difficulty. This is the stack I used for Magic-1's original OS. It's getting closer to working, and at the moment it seems to correctly respond to a single ping, but then something hangs. On the other hand, I have successfully run several tests of pumping large files across the serial port at 38400 BAUD, all the while running CPU benchmarks in the background and performing other disk I/O. The handshaking seems to work just fine - we'll get a burst of data, stop for a while and then take in another burst. I think my next step will be to go back to a untouched copy of the uIP code (rather than start the port with my old Magic-1 copy). I played some hacky tricks to improve the performance of the stack, and the things I did might not play well with Minix. Also, it's just about time to break out the logic analyzer for some performance measurements. If I remember correctly, my logic analyzer has a feature that will enable me to time and then plot the periods in which interrupts are disabled. I've done quite a few reviews of the code and believe I am keeping locked regions to an acceptable level, but I'd feel better with some actual measurements. 8/14/2007I'm now back from vacation and am resuming work on the port. I decided to completely rewrite the rs232 interrupt handler to take advantage of the 16550 FIFOs. After a few frustrating coding/debugging sessions, it seems to be working just fine. The big problem I ran into turned out to be in tty.c's in_process(). This code is responsible for copying incoming data from the low-level driver's buffer to the primary tty input buffer. For some reason, it was silently discarding data when the buffer filled up and the tty was in canonical mode (but not raw mode). I'm probably missing some subtlety, but I can't imagine why it would do that. Anyway, I've changed to code to not silently discard the data and everything seems to be working just fine. It may be that I'm the only person who has ever encountered that particular bit of code because of Magic-1's relatively slow computational speed relative to the high UART speed of 38.4K BAUD. The new rs232 interrupt handler is pretty fast, though I could probably get about 25% speedup by recoding it in assembly. I ended up deciding to have the entire handler run with interrupts disabled. I'll redo the calculations be be sure, but I believe that it is fast enough that one serial port won't starve the other and cause data overflow, and I shouldn't have any lost clock ticks. Next up I want to build and test zmodem binary file transfers. Getting that working will make life a lot easier. Right now I have to jump through some awkward hoops to copy files to and from Magic-1's file system. 8/11/2007Haven't made any code changes, but have given some more thought to the issues around getting the best serial I/O. Here's a brain dump of my current thinking:
8/6/2007Just wanted to jot down a few thoughts on possible ways to reduce the maximum latency for responding to serial port input (needed to get the high communication speeds I'm after):
Anyway, by implementing the above, I should be able to dramatically reduce the worst-case interrupt responce latency to a small and manageable amount. That, in turn, should allow me to run the UARTs in FIFO mode at a much higher speed than 4.09 Mhz CPU would generally support. 8/5/2007I'm almost, but not quite, ready to declare a successful Minix port. It's running pretty well, and I've got all but a handful of the Minix applications ported over (the vast majority required only a recompile). The biggest remaining problem is related to interrupts and the rs232 driver. Because the serial ports are the primary modes of getting data on and off of Magic-1, I need them to reliably run at the highest possible speed. This was probably the area I spent most of my time on when I wrote the original Magic-1 OS/monitor, and it took me quite a while to get it working well. Things are not working so well right now with the Minix rs232 driver. When I push a big chunk of data into the machine, the driver hangs. There is a hardware handshaking mechanism by which the driver tells the sender to stop sending data. I suspect that's where the problem is. The key to making this mechanism work is to ensure that the driver can quickly respond to incoming data and shut off the sender before buffers overflow. Right now I've got too many places where I'm masking interrupts (and for too long). Also, the Minix rs232 driver is intended to support an old UART which does not have a FIFO - something that has to work to get the good speeds. Anyway, the first step will be for me to carefully examine and eliminate or reduce the periods where interrupts are disabled. Next up, I have some ideas about how to give priority to responding to incoming serial port data in code regions that must otherwise be locked. As part of this process, I may eliminate the existing code that allows multiple interrupt handlers to share a single interrupt line (something that x86 needs, but Magic-1 does not). The other big issue is that I have run into code size problems with vi. Vi has a lot of 32-bit arithmetic, which my lcc port handles poorly. As a result, vi won't fit into a Magic-1 64 Kbyte code space. I've got to address this either by improving my lcc retargeting or by supporting code overlays (or both). I won't be able to consider this a real system until I have something that looks like vi. Some other minor issues that other folks might run into with similar porting efforts:
Much, however, does work pretty well. I've got two serial ports and thus support two simultaneous sessions. Cron is running, man pages can be displayed, local mail works, fsck fsck's when appropriate and so on. Besides vi, the only other important missing pieces are awk (code too big because of my poor lcc floating point support) and the tcp/ip stack (inet server - also code too big because of my poor lcc 32-bit integer support). I plan on fixing those two via a code overlay mechanism. Oh, and I've also got a workaround in place for the Minix shell: ash. I haven't debugged it yet, but ash hangs when I use the "readline" package - so I've disabled that for the moment. The last issue is speed. The system is painfully slow - it can take several seconds for even the simplest of commands. This seems less bad when I remember what machine speeds were like 20 years ago, but I believe I can make significant improvements. First off is just tuning, which I haven't done yet. i'm sure I can significantly speed up the physical memory copy routine for message passing. Second, I never got around to supporting bss in my tool chain (I just add bss to initialized data). This means I have to copy more from disk than is really necessary when I load a program. Finally, the biggest improvement should come from either implementing demand paging and copy-on-write or something like the old vfork() hack. Fork/exec is much, much slower at the moment than process launch is with my old monitor/OS (which did demand paging and copy-on-write). Fixing that alone should go a long, long way towards making the system feel more responsive. Oh, and other other thing: there is no native tool chain, and probably won't be. All of the system is built using a cross development environment. Without too much difficulty, I could get the linker, object file tools, libraries, cpp and the assembler running natively. However, lcc is awfully large - too large for my 64K code and 64K data limitations. I'm not especially interested in massaging lcc to make it fit - this is a hobby project after all and that sounds too much like real work. However, I have toyed with the idea of creating a web service wrapper around lcc. In this scenario I'd have the linker, assembler, etc. running natively. The cc driver, though, would bundle up and compress the input source file, squirt it over to my Linux box where it would be compiled with the cross-lcc compiler. The results would then be shipped back for linking or error reporting. We'll see. Once I get things a bit more stable, I'll open the machine up again for guest logins. I've got a busy week coming up, so I doubt I'll be able to make much progress this week. Still, it looks pretty good. 7/28/2007WooHoo!
7/26/2007Mostly good news tonight. I took a look at my sendsig code and noticed that I had neglected to change the sigcontext structure to reflect a change I made earlier to how I was handling the page table base register in the proc structure. One simple edit later and it appears that at least basic signal capabilities work (I haven't done extensive testing yet). Then, I decided it was time I started running a shell as my simple test program. I now realize that I had not ever previously tried to compile "ash" - the Minix shell. It's a bit of a mess when dealing with a cross-compilation environment - the make process includes the building of a half-dozen or so native programs to generate and massage the source code. Also, ash on the 16-bit x86 version of Minix almost completely fills up a 64K code segment. Anyway, I spent most of the evening trying to build ash. Some of the native build actions I was able to perform using gcc and my x86 build host - but some I felt safest running on Magic-1. I never quite got it to completely build. Ash uses setjmp and longjmp, which I haven't implemented yet. However, I did go ahead a stub them out to see how big the code was. Good news: ash will fit on Magic-1. It's even slightly smaller than the x86 version. One of my Magic-1 instruction set architecture goals was code density equal to or better than x86 for exactly this reason. So, I'm going to have to get setjmp/longjmp working before I proceed with trying out a full-featured shell. Meanwhile, though, I cobbled together a trivial shell. That's now running on Magic-1 - and I'll probably flesh it out enough to handle the needs of the boot process. Ash is complicated enough that I'd prefer to tackle it after the rest of Minix is booting. 7/25/2007Just a few small changes to my C start-up code, and exec() now works. I've got a nice test that forks and execs - looking good. Next up is working out the problem with sendsig. There's a bit of machine/calling convention specific code there that I've likely gotten wrong. Shouldn't be too hard to fix. With luck, I should be in a position to start working through the real INIT code by this weekend. 7/24/2007Tried out fork() and exec() last night. After one minor change (the copy of the proc table entry for the child wiped out its page table base), fork appears to work just fine. I've had to do a bit more work on exec(), which isn't surprising. Magic-1 uses a quite different calling convention as well as a.out format than x86 Minix. However, it now appears to be basically working. I'm sure I'm not yet getting argc, argv and envp set up quite correctly - but they should be pretty close. I did run into some odd behavior with sleep(), and possibly exit(). Earlier I did a quick test for sleep() and it seemed to work, so there may be a problem in fork or exec that is manifesting itself in sleep(). I'll track those down next, as well as finish off the argument setup for exec. The way I'm testing things is to replace INIT with my test program. 7/23/2007Just a quick update - shortly after writing last night's diary entry I noticed the primary problem with the TTY. The code in rs232.c was written for an early version of the UART I'm using in Magic-1. Magic-1 uses a 16550, which has a built-in FIFO. The one Minix is coded for uses the same command set, but doesn't have the FIFO. Anyway, the FIFO adds some extra status bits in the interrupt status register, and this was causing the switch statement in rs232_handler() to ignore all interrupts. After masking out those extra bits, things started working pretty well. I've still got some issues with nested interrupts, which I'm working around at the moment by blocking all interrupts for longer than I'd like. But, so far, so good. I've got reliable interrupt-driven TTY output and input. Just for kicks, I replaced INIT with a slightly modified version of ps. After all the tasks and servers are initialized, ps is launched. Here's a screen dump:
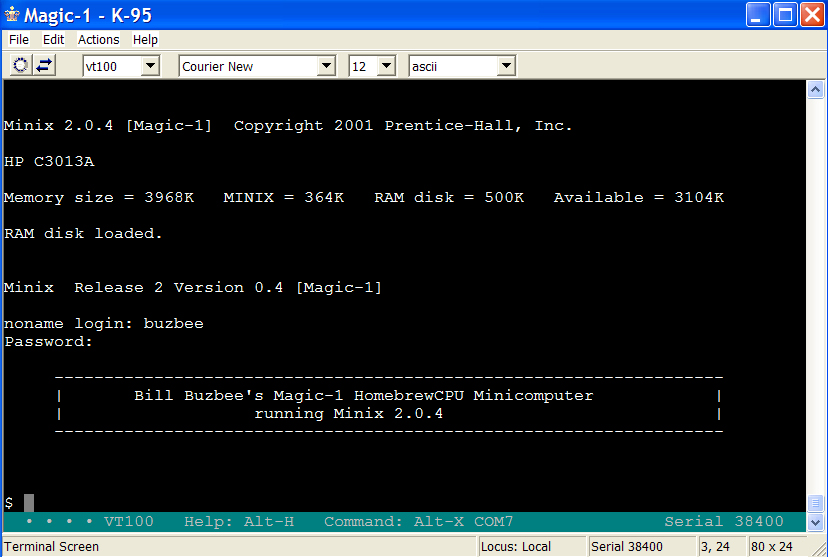
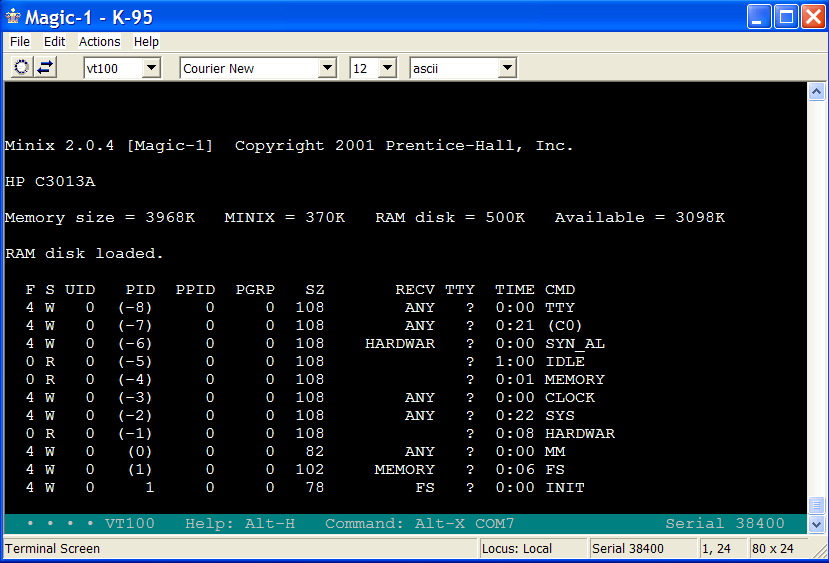
I also had time this event to do some minor file I/O testing. I added /etc/rc and /etc/ttytab to the skeleton Minix file system and then put some code at the beginning of INIT to just open those files and copy them to stdout. Worked like a charm on first attempt. There isn't that much left before I start working through the real INIT. The next thing is to take a close look at fork() and exec() to make sure I've correctly reworked the low-level code to handle Magic-1's memory allocation model and a.out header changes. 7/22/2007Steady progress, though I didn't get to spend much time on the project this weekend (the final Harry Potter book was released early Saturday, and kids (and I....) spent much of the weekend reading). Anyway, a lot is working. Magic 1 currently:
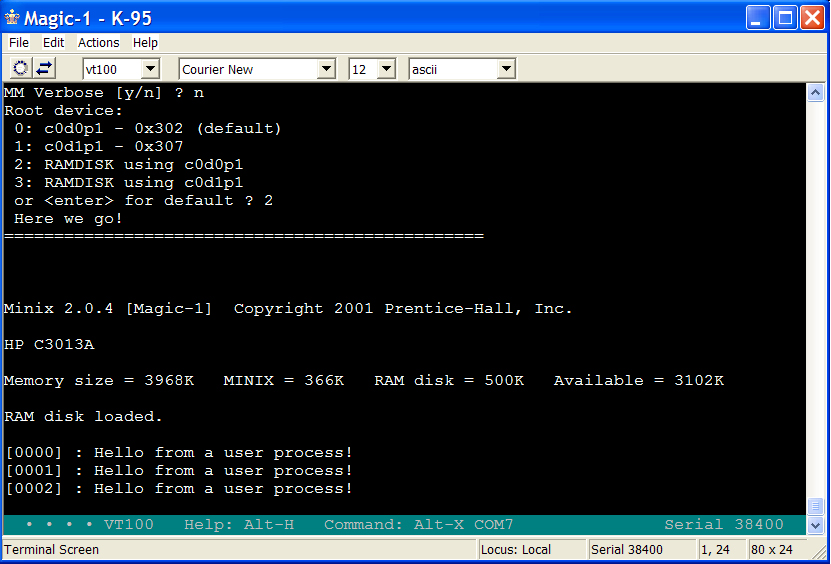
Here's a screenshot of a Minix boot. I've told the bootstrap loader to use a RAM disk for the root device, and initialize it with a copy of partition 1 of hard drive 0 (my 500KB Minix file system image). |
| Test loading of RAM disk | |
| Test and enable basic interrupts | |
| Implement masking of individual interrupts to avoid kernel stack overflow on nesting | |
| Bootstrap file system to include devices (ram/null/kmem,c0,tty,etc.), basic directory structure and the applications needed by init (getty, sh, etc.). | |
| Test rs232 tty driver with interrupts enabled. | |
| Test hard drive driver with interrupts enabled. | |
| Clean up interrupt/fault/syscall path - in particular the page table base handling. | |
| More extensive testing of virtual memory copy routine. | |
| Fix execve() to understand my a.out format and memory allocation | |
| Test/verify signal delivery mechanism | |
| Add argv/argc support to user-mode crt0.s (ctart routine). |
With luck, I may see a login prompt this weekend.
Good progress - we're almost successfully through kernel initialization. The Memory Manager and File System servers do most of their initialization. I've built an empty Minix file system on a Minix partition on the hard drive, and FS successfully decodes the partition table, read the superblock and does a basic sanity check on the file system. I've still got a few workarounds in place, so the next step is to go back and clean those out. After that, I need to build out the file system so Init has something to load up.
Spent quite a lot of time this weekend debugging. The current state of the port is broken, but making steady progress. In a significant change early in the weekend, I decided to change all of the kernel tasks (TTY, CLOCK, SYS, etc.) to run in user mode rather than kernel mode. There are benefits and problems with doing this. On the benefit side, it makes my user<=>kernel mode switches much nicer, and the interrupt, trap and syscall layer significantly simpler. On the problem side, kernel mode tasks can no longer directly execute privileged instructions.
The way things now work is that each task gets its own private page table (via a unique page table base). However, all of the mappings for the various tasks point to the same physical kernel text and data pages. In other words, although technically "user mode", the tasks have full access to kernel memory. To allow the tasks to execute privileged instructions, I've had to add a half-dozen or so fast system calls. These syscalls are special in that they may only be executed by tasks. I've also made them very quick - usually less than a dozen instructions. To simplify things, they are executed with interrupts disabled and never block.
Now, more info on the port status. Earlier I'd reported that I was getting all the way to INIT. This was sort of true, but mostly false. I was getting to INIT, but only because there was a problem in correctly setting the system call return value. What was happening was the each task would launch and print an opening message. However, after printing the message the task would incorrectly stay blocked and so the next was scheduled. Little else happened, until we got to INIT.
Once that was fixed, we had lots of steady progress until the initialization code of the server processes: MM (memory manager) and FS (file system). Most of my debugging time was spent getting the driver for my IDE hard drive working. Currently, it is working well enough to open the root device, correctly identify the hard drive and read the partition tables.
Oh, and I'm still running with interrupts disabled. On Saturday I worked that problem a little bit and was able to get them mostly working. There were, however, occasional problems with nested interrupts. I decided to defer debugging that until more of the other code is working.
Anyway, the boot process is now dying in the memory manager, shortly after it asks about the size of the RAM disk. I haven't pinned it down completely yet, but there appears to be a problem in my mechanism to perform physical memory copies. I seem to be able to correctly get messages from the servers, but something appears to be going wrong when I send the message back. My best guess of the moment is that I'm not correctly setting up the page table bases on context switches in some cases.
Random porting notes:
| While designing Magic-1, I typically tried to minimize hardware if I believed I could handle a capability in software. I'm now regretting some of those choices. In particular, the page table base and page table entries are write-only. I can set them, but cannot read them back. My belief was that I could just keep track of what the current values were in software. This is probably true, but is a major pain - particularly the page table base. I'm considering adopting a convention that a process's page table base will be (by convention) stored into a slot in the stackframe_s record at each trap/interrupt, and then restored prior to a reti. | |
| It would be useful to redo the microcode such than when a trap or interrupt is taken, the DP register is automatically cleared (after its previous state is saved in the save_state record on the stack). I should be able to do this without cost. | |
| When doing a normal physical memory copy, we cannot get a page fault (because the copy is done by setting up a temporary page mapping defined to be present and readable/writeable). However, I do have a couple of instructions that do a physical memory copy by using as either the source or operand address as a virtual address to be mapped to physical memory using the hardware address translation with the current ptb. This hasn't turned out to be as useful as I hoped because it is possible to get a page fault. The simple way of avoid this is to make sure the page table entries are valid before copying, but that somewhat negates the intent of having a fast copy instruction. The other way to handle this is to go ahead and blindly copy - but have the kernel be aware of a page fault in this special case. It would interpret a page fault in this case as bad system call parameters. |
Things are looking good. The syscall path seems to be working well, and I'm making it all the way to INIT. Along the way I ran into a nasty LCC C compiler bug dealing with a somewhat esoteric rule about promoting integral types in ANSI C. In most cases, short unsigned types are automatically converted to wider signed types. LCC, however, was doing this conversion in one special case when it shouldn't have (the case in which unsigned shorts are the same size as unsigned ints). This is an odd case, but one that exists for Magic-1. Anyway, that's fixed now.
The next item is to get the interrupt code working. I've had it disabled for a while because I was hitting some infinite debugging printf loops. It is possible, though, that the interrupt code is correct and my debugging printfs were wrong. Anyway, time to check that out. After that, I need to bootstrap a minimal Minix file system so that I can more fully test the TTY task.
Here's a listing of a Minix boot as it exists today. I've added some debugging printf()s to show when the various kernel tasks get control, initialize themselves and then block awaiting messages. Note that the printf()s coming from the server tasks (mm and fs) are successfully doing systems calls to the SYS task in order to do the printf()s. The portion of the listing starting at "***** Minix boot *****" comes from the boot loader. Everything after "Jumping to remap...." is coming from the Minix Kernel.
*********** Minix boot **************
Loading MinixKernel
22 text pages starting at 64, 14 data pages starting at 86
......................
..............,,,,,,,,,,,,,,,,,,
Loading MinixMM
8 text pages starting at 118, 8 data pages starting at 128
........
........,,,,,,,,,,,,,,,,,,,,,,,,
Loading MinixFS
19 text pages starting at 158, 29 data pages starting at 177
...................
.............................,,,
Loading MinixInit
4 text pages starting at 209, 2 data pages starting at 213
....
..,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
================================================
Here we go!
Jumping to remap supervisor page table and launch Minix
Boot monitor variables;
memory=20000:3E0000
verbose=off
Minix main - before restart
--pid --pc- ---sp- flag -user --sys-- -text- -data- -size- -recv- command
( -8) c7c 3868 0 0 0 128K 172K 108K TTY
( -7) 6ae8 3a68 0 0 0 128K 172K 108K (C0)
( -6) 5b2a 3b68 0 0 0 128K 172K 108K SYN_AL
( -5) 1a2 3c68 0 0 0 128K 172K 108K IDLE
( -4) 3da8 3d68 0 0 0 128K 172K 108K MEMORY
( -3) 4e94 3e68 0 0 0 128K 172K 108K CLOCK
( -2) 771a 4068 0 0 0 128K 172K 108K SYS
( -1) 0 4068 0 0 0 128K 172K 108K HARDWAR
( 0) 0 fffa 0 0 0 236K 252K 80K MM
( 1) 0 fffa 0 0 0 316K 354K 102K FS
1 0 fffa 0 0 0 418K 426K 72K INIT
** TTY task **
Minix 2.0.4 [Magic-1] Copyright 2001 Prentice-Hall, Inc.
** FAASSE Winchester Hard Drive Driver **
** SYN_ALRM task **
** MEM task **
** CLOCK task **
** SYS task **
Memory Manager Server
File System Server
- Invoking INIT, cold restart
Okay, so I couldn't wait until the weekend to fiddle with the port some more. After fixing a couple of simple problems (and one more significant one), Minix runs all the way to INIT. There are still some problems, but all of the kernel-mode tasks successfully initialize and block for messages and the user-mode servers (fs and mm) initialize and *almost* successfully do system calls to sys. We eventually wind up in INIT, which either hangs or blocks - not sure which.
The next problem to fix is an issue with virtual to physical address conversion. At the beginning of FS and MM, I've added a debugging printf() which generates a system call to the SYS task. This call is successfully made, SYS unblock and retrieves the message. it correctly decodes the message to determine it's a SYS_PUTS request and attempts to print out the string. However, I think I'm not converting the virtual message address in MM's address space to a physical address that SYS can use. Should be easy to find and fix, when I find the time to work on it. There are several virtual<=>physical conversion routines that I need to debug and verify. Once those are good, I should be very close to running.
The one significant problem I found was the cause of the system call debug trace weirdness I noticed yesterday. And, it points to a design flaw on my part. When I designed Magic-1's context switch mechanism (the SP/KSP thing I mentioned earlier in this thread), I took the position that kernel mode code would never do a system call trap. Further, I designed for only two modes: supervisor mode and user mode. The problem here is that some (perhaps most) of the Minix kernel mode tasks must run in supervisor mode - and they do system calls. I'll skip the esoteric details, but the upshot is that the system call handler now has to detect whether the system call was made by a supervisor mode task. If so, it must copy the syscall trap save-state structure from the kernel stack to the task's stackframe_s structure in the proc table. It's not a big deal, but it is a bit ugly and I don't like it.
I might be able to work around this by making all but one of the kernel tasks run in user mode. I can easily give those tasks full access to kernel memory via my page table. The only issue is that only supervisor-mode code can do physical memory copies. If I only allow SYS (which has the phys_copy code) run in supervisor mode, I would need to add a lightweight phys_copy system call to only be used by tasks. The other, better, option would have been to implement three or more protection domains (rather than two), and have something like user mode, task mode and kernel mode. Task mode would be similar to user mode, with the exception that it would be allowed to execute the instructions needed to do a physical memory copy.
Oh well, that's something to play with later. My workaround is good enough for now.
Major progress today - the Minix kernel is partially up and running. It appears to be correctly initializing after getting control from the boot loader, and then it successfully schedules and runs each of the kernel-mode tasks. Each task appears to correctly initialize itself, and then block waiting for messages. However, there are a few problems left to work through:
| Interrupt path is broken. Something is wrong in the interrupt path, so I've just disabled interrupts in order to continue making progress on the system call path. The error appears to be a memory corruption problem that occurs shortly after the TTY task sets the UART interrupt handler. It is also possible that I'm causing something bad here by the way I'm doing kernel printf(). To give myself the ability to do debugging printfs before the TTY handler is active, I coded a putk() that bypasses the TTY task and directly output chars to UART0. It's possible that I'm causing an endless interrupt loop here with my debug statements. Anyway this is the next thing I'll debug. | |
| System calls. The only system call used so far is receive message (which then blocks the tasks because there are no messages yet to receive). This appears to be working, but in one of the debugging printf()s in the syscall path looks odd. Need to track this down to see whether it's a problem in the debug printf, or a real problem. | |
| User-mode code transition. Magic-1 seems to fly off into the weeds when all of the kernel mode tasks have been run (and block), and the user-mode server code starts to run. It's possible that things are working and I just don't know it - but most likely there is a problem there. |
Anyway, things are looking good. It will probably be a while before I can devote some time to make more progress though. Perhaps next weekend.
Well, finally attempted to boot the kernel. I had a bit of a hard time getting the transition from the old Magic-1 OS to Minix, but I believe I'm finally there. It's quite tricky code. While running in supervisor mode, you need to load the Minix images to their home physical pages, and then comes the difficult part: you've got to remap the supervisor's page table to map the virtual memory space you're currently occupying to the newly-load Minix image. This involves relocating key bits of code to a 'safe' page (i.e. - one that isn't going to be relocated) and then doing the remapping. Complicating matters is that when the code on this page is executing, you've lost all access to the old stack, code and global data. Output to the terminal isn't available, so it's just pushing debugging messages through the front panel's POST code display and executing halt instructions to see how far you're getting.
Anyway, I believe I am successfully transitioning to the Minix code now. Next up is getting the Minix "kprintf" to work so I can dump debugging messages directly to the terminal before the tty task is active.
Just a few random notes to remind myself in the future when I get around to supporting overlays:
| The needed changes will be largely isolated to the linker & the kernel's exec(). | |||||||||
| Add a linker command-line option to tag .o's (or .a's) with an overlay name. May want to have a variant that points to a file describing the .o<=>overlay mapping. | |||||||||
| When a tagged .o is processed, its code is placed in an overlay region with all entry point names changed in the symbol table by adding a $ov[n]_ prefix. A transfer stub is then added for each entry point with the "real" name in the primary (shared) text section. A symbol for each stub will be added to the symbol table, so future references will resolve normally to the stub. | |||||||||
| Each transfer stub will be assigned an integer index into a branch table that will be allocated and added at or near the end of linking in the data space. | |||||||||
| The transfer stub will do something like:
ld.16 b,#INDEX_NUM | |||||||||
The code at $do_overlay_branch will use the index to the branch table, which
is composed of pairs of overlay number, target address. That
code will:
| |||||||||
| When the target procedure returns, it will return to $do_overlay_return, which will restore the calling overlay using the data stored in the overlay stack. | |||||||||
| [Note - the above code will short-circuit this process and jump branch to the target if the current overlay number is the same as the target. | |||||||||
| The starting address of the overlay won't be known untill we're done adding code (as all overlays must start above the highest address in the common code section. I don't think this will be a problem. | |||||||||
| The actual branch table will live in the data section. The linker will have to keep track of all of the entries and emit this table after all of the object files have been processed (and we know how many there are and what their final addresses are). | |||||||||
| We want to make sure the user-mode code has no idea of the actual page table base used in the kernel, so the overlay switching mechanism will use overlay numbers rather than the actual page table base value. The kernel will keep a mapping associated with the process (which likely implies that we'll have a smallish fixed maximum number of overlays) to keep things simple. | |||||||||
| I'll need to change the a.out header slightly to note the presence of overlays, as well as the kernel's proc table. | |||||||||
| Changes will also be needed for ar, nm, nlist, etc. - but these should be fairly minor. | |||||||||
| in the end, I'll want to have the linker be clever enough to directly resolve intra-overlay calls - but for debugging purposes it will be best if I get it working first where everything goes through stubs. |
On the main Minix port front, I'm working my way through fully understanding what information needs to be passed from the bootloader to the kernel. Getting pretty close to actually attempting a kernel boot.
The partitioning of inet should be fairly simple. First I'll use my Magic-1 "nm" to dump the imported and exported symbols from the various .o's that make up inet. Then, a simple Perl script build a graph (and I may even get fancy and make a nice GraphViz picture.
The other issue is how to deal with nested overlay switches. Normally, a 16-bit address is sufficient to branch to, and to return to after a procedure call. With the overlays in place, though, a code address becomes a pair: <16-bit address:overlay number>. So, when you make a procedure call to a routine in a different overlay, you need to save not only the return address, but the return overlay number as well. The clean way of handling this would be to use a scheme similar to that used by shared library calls. Each activation record that is pushed on the stack by a procedure would include a frame marker record with space to save the overlay number of the return. (You can't just push it on the stack because that would screw up the formal parameter offsets for the callee). I'd rather not do this for Magic-1, though, because it would waste a word of stack space for each non-overlay call.
At the moment, I'm leaning towards allocating a fixed-size overlay return stack that would be manipulated by the call and return stubs. I'd have to make sure that I wouldn't overflow it - which in this case I'm pretty sure will be easy to do. Or, I might change my mind and alter Magic-1's calling convention to include a frame marker record.
I've given the inet code overflow issue a bit more thought, and I think it isn't going to be a problem after all. The solution is a common one from the days of 16-bit address spaces: overlays. The general idea is that you'd have a base of code that is generally required, and then swap in and out excess code. This sounds pretty gross - but it turns out that Magic-1's memory management mechanism can allow us to have a very efficient overlay system. We don't need to actually copy the code in and out of the swap buffers. Instead, all we have to do is set it up properly and just change the page table base address register. My first estimate is that an overlay swap will only require the execution of about 20 instructions.
What I'll need to do is a bit of static analysis of the inet code tree to determine a common base of routines that are needed by all overlays. Then, partition the rest of the code into overlays (my guess is that I'll have one common base and three overlays). Each of the functions in the overlays will be assigned a fixed integer ID which will identify it's branch table entry (which will exist in the common region). The branch table entry will include the function's overlay ID and it's virtual address within it's overlay. Each routine will then be replaced by an assembly stub that does something like:
needed_overlay = branch_table[TARGET_FUNC_ID].overlay_no;
if (needed_overlay != current_overlay) {
sys_swap_overlay(needed_overlay);
current_overlay = needed_overlay;
}
jump_to (branch_table[TARGET_FUNC_ID].func_address;
I'd need to add a new system call that would simply make sure it was being called by inet and then set the new page table base and return. Very fast and simple. The key to this mechanism is that all of the overlays (and the common code) share identical page table entries for all data pages, as well as the code pages that hold the common routines. That way data references are the same regardless of which overlay is active. The difference comes in a region of the code virtual address space. This region is mapped to different sets of physical memory pages for each overlay.
The hardest part of this will be to enhance the linker and build system to automatically generate the overlays.
Good news and bad news on the Minix port front. The good news is that things are moving along nicely. I'm successfully building the kernel, mm, fs and init. The low-level assembly layer for traps, interrupts and context switches is largely done. I've also done some preliminary testing of Magic-1 native programs that examine the a.out header. I'm not far away from attempting to load the kernel (and the fs and mm should follow shortly. The bad news is that I finally got around to attempting to build inet - the ethernet server process. As things stand now - it isn't even close to fitting. I've only got 64K bytes of addressable code space per process, and my initial compile of inet runs more than 90K bytes. This is much bigger than the 16-bit x86 version (which just barely squeezes into 64K).
One of the goals of my ISA design was to meet or exceed x86 for code density - specifically to avoid a problem like this. Magic-1 does look very compact, and seems to beat x86 for 16-bit integer code. However, what's happening in inet is that there is a lot of 32-bit arithmetic. My lcc implementation of 32-bit ints is not very good. it works, but a lot of useless code is generated. That's my problem with inet. The way I implemented 32-bit integer arithmetic using lcc was to lie to lcc and tell it that I have native 32-bit registers. I then map those "registers" onto stack locals. It's a bit of a kludge, but it enabled me to get long int support fairly easily.
I guess if I'm going to get networked Magic-1 Minix, I'm going to have to revisit my code generation strategy. There are a couple of approaches I could use. I'll likely start with a mode in which all 32-bit operations are handled via a lightweight runtime procedure call (what we used to call "Millicode" at HP). Additionally, I think I could recover much of what I need by introducing a peephole optimization pass. A lot of the junk code I'm emitting is memory copies from one "register" to another. Another possibility is to split inet into a pair of server processes. We'll see.
I've been making good steady progress on the kernel port. My approach has been pretty leisurely - I've generally been spending a half-hour or so while having my morning coffee working on the low-level assembly code that makes up the trap/interrupt/restart layer of the kernel. I've found that when doing this kind of code (kernel mode assembly is hard to debug), I've had the best luck by writing it and not immediately attempting to run it. Instead, I'll let it sit overnight and then do a deck-check code review the next day.
I still haven't attempted to actually execute this code - but I'm feeling pretty good about it. Several times over the last week or so I've changed my mind on how to deal with Magic-1's inability to mask a single interrupt (it's either all or nothing). I think I've settled on a scheme that looks a lot like what the existing code does to recognize nested kernel reentries. Each interrupt will have an associated reentry counter that is incremented when the interrupt arrives. If the low level code sees that an interrupt is already being handled, it will just return. When an interrupt handler completes, it will look to see if there were any pending interrupts. If so, it will run again. These counters will be visible to the handler, so in some cases the nested interrupts can be dealt with all at once instead of having to rerun from the beginning. For example, nested clock interrupts are handled as "lost_ticks" than can simply be accumulated. I might also decide to have the rs232 handler check for newly arrived interrupts in the middle of it's main loop.
A few braindump items:
| In practice, the kernel code must run with a data pointer (DP) base of 0. Rather than have all of the trap/interrupt handlers explicitly set DP to 0 on entry to the kernel, it would be an easy matter to just have the trap/interrupt microcode clear DP. | |
| Similarly, it would be convenient if a register was automatically loaded with the trap/interrupt vector number. The microcode already has this info (which it needs to locate the target vector), so why not just stuff it in a register B? I'll have to be careful, but I think I can rewrite the trap/interrupt microcode to do both of these things at no additional cost (and at worst, 2 cycles). | |
| I continue to be very happy with my design of the context switch mechanism. It's simple, cheap and effective. It consists of a shadow stack pointer which tracks the real stack pointer while Magic-1 is in supervisor mode, but does not change while Magic-1 is in user mode. it just cost two 8-bit register chips and a couple of logic gates. However, it gives us a clean mechanism to dump the interrupted user-mode state into kernel-land data structures. It was one of the first things I designed once I decided that Magic-1 should be capable of running Minix. |
Lots of good progress this weekend. I'm just a few routines away from a first attempt at booting Minix. Pretty much all that is left is the low-level interrupt code, sigreturn and fleshing out some of the memory allocation code. My best guess is that I should be able to attempt first boot within a couple of weeks.
One of the issues I've had with interrupt handling is that Magic-1 was designed to either block all interrupts or none. Minix on x86 expects to be able to individually mask interrupts via the interrupt controller chips. When I designed the interrupt system, I decided to go with my simpler approach, expecting that I could work around it in software. I believe this is true - I can work around it, but in retrospect I think i could have added individual masking with very few extra gates.
Anyway, my plan is as follows:
| Each maskable interrupt will have an associated "mask" bit in software. | |
| Each maskable interrupt will have an associated "pending" bit in software. | |
| When an interrupt arrives, the handler is invoked with interrupts blocked by hardware. | |
| The handler will immediately look at its "mask" bit. If set, the handler will set the associated "pending" bit and the do a return from interrupt (which will re-enable interrupts). If there was already a pending interrupt, this new one will be dropped on the floor (which I think is okay in this situation). | |
| If the "mask" bit is not set, the handler will proceed with its normal operation. At some point (early on) it will set its own "mask" bit and then re-enable hardware interrupts. | |
| When the handler is complete and intends to return, it will first block all interrupts in hardware. | |
| Next, it will clear the "mask" bit. | |
| Finally, it will look at its pending bit. If set, that means that an interrupt arrived while "masked". In this case, we reset the pending bits and jump to the beginning of the handler to start the process over again. | |
| Otherwise, do a normal return from interrupt (which will automatically re-enable hardware interrupts). |
The mask and pending bits are critical resources, and so must only be accessed as a critical region. It is sufficient to block hardware interrupts before accessing them. There is a possibility of starvation here if a rapid stream of interrupts keeps a handler from ever returning. However, with Magic-1 as it currently exists, in practice this would only be an issue for the real-time clock's heartbeat timer when running with a slow clock. Fortunately, the heart-beat timer is handled differently and won't go through this path.
The other issue of the moment relates to memory handling. Minix uses a very simple memory allocation scheme. There is no paging, and processes use contiguous regions for code and data. A consequence of this is that to conserve memory, there is a special field in the a.out header to tell how much memory to allocate for stack and heap. I don't like this much - it seems a bit inelegant. So, when I defined my a.out header, I omitted this field. My intention was to support a simplified paging mechanism that would allocate stack and heap on demand. This remains my intention, but I think it best to just use the normal Minix scheme during bringup. I can add paging later.
However, rather than just using the Minix scheme as-is, I decided to take advantage of one of the features I built into Magic-1: the data pointer (dp) register. Although I'll probably never implement shared libraries for Magic-1, I very much like the idea of position independent code. One way of supporting position independent data access is to do all accesses relative to a register base pointer. This is what Magic-1's DP register is for. In many computer architectures, there is a form of absolute addressing. For example, if you have a global defined as:
int foo;
... and later on you access it as:
foo = 123;
the code generated needs to get the address of foo and store 123 into it. Some examples of doing this using absolute addressing would be:
ld reg,foo ;
Load the address of "foo" into reg
st (reg),123 ;
Store 123 into foo
... or
st (foo),123 ; Store 123 into address foo
Now, assume for the moment that the above code is in a shared library and can by executed by multiple processes - each with their own notions of virtual address space. That code will only work if 'foo' lives at the exact same address in each process that accesses the code. Not good.
Consider now the way Magic-1's global memory accesses are defined. We have a special register, "dp", that acts as a base pointer for all global accesses. The Magic-1 code for the above example is:
ld.16 a,123 ;
st.16 foo(dp),a ; Store 123 into foo
In other words, the symbol 'foo' refers not to the absolute address of 'foo', but rather to its offset relative to the beginning of the program's global data segment - which is pointed to by the register dp. So, to find the real address of 'foo', Magic-1 will add the symbol foo to the contents of dp as part of the store instruction.
This may sound a bit strange, but it does make life easier in some cases - particularly for shared libraries and position independent code. If in the above example foo is actual a static variable associated with the shared library code, then that code can be easily accessed by multiple processes that have mapped the shared library code and data into whatever virtual addresses are convenient for them. All that has to happen is that the dp value for the shared library is set as part of the shared library calling convention. The offset of foo from the beginning of the shared library's static data segment will be the same for everyone, but the actual virtual address of each process's private copy of foo can all be different - based on whatever dp value is used by each process at runtime.
Anyway, that went on a bit longer than i intended. The upshot of this is that I can take advantage of this feature for my temporary usage of the Minix memory model. The field I added in my a.out header is a count of unmapped data memory pages at the beginning of a process's data space. For example, if a program needs only 4 Kbytes of stack and heap, I'll mark the header to have the first 30 2K pages (60 Kbytes) to be unmapped in the page table. Further, this will mean that the starting DP value for the program will be 60Kb. As far as the program knows, its data runs from addresses 0 through 4K, but in reality it will end up from 60K through 64K.
The other way I could have done this (in fact the normal Minix way), would be to have the processes data start at 0 and end at 4K. That would also mean that I'd have to use a starting SP of 4K (potentially different for each process). Instead, I'll always have SP start out at 64k+1 and adjust DP.
In truth, it probably would be easier to just do the normal Minix thing - but I like my DP scheme, and this is an excuse to use it. Also, the unmapped page slot in the header is something that I will be using later to ensure that I can generate a segmentation violation on a null pointer dereference.
Pretty busy weekend, so I spent only a small amount of time fiddling with the Minix port effort. Mostly I've been working towards getting the kernel to cleanly compile. I still haven't worked out all of the details, but am mostly using this effort to help me distinguish machine dependent code. I'm down to about a dozen missing entry points - most of which I understand pretty well and shouldn't be much of a problem.
The bulk of the project time was spent on implementing the 64-bit arithmetic subset that the kernel needs to address large hard drives. Magic-1 will certainly never need such a thing, but I decided it was cleaner to implement the 64-bit support than to just use 32-bit arithmetic in the drivers. Anyway, it didn't take too much time. I've got all of the routines (x86 equivalents: /usr/src/lib/i86/int64/*.s) coded and have completed testing of the important ones (add64, sub64, mul64, div64u, rem64u, cmp64). I may need to revisit this later, though. Div64u is in the hard drive controller path and is really slow. I took the easy way out and did a fairly inefficient implementation. If I hand-coded it in assembly I'm sure I could at least triple the speed. Alternately, I could also just add a check in the beginning to see if it could be handled by my normal 32-bit division code (which is mostly tuned). Something to keep in mind once I've got Minix running and am looking to speed up disk I/O.
Sometime soon I'm going to need to make some bootstrapping decisions. Magic-1 comes up in supervisor mode with interrupts disabled and paging off. There's a fairly complicated sequence of events needed to turn paging on, but that's been working for quite a while and is currently implemented in the boot rom. Minix on the x86 has to go through similar contortions to boot into protected mode. For Magic-1, though, I'm leaning towards continuing to have the boot rom deal with the transition. In other words, when Minix on Magic-1 starts up, it would begin life already running with paging enabled.
In some ways, this makes life easier. However, there are some complications - particularly when the Minix monitor needs to load a kernel image. The primary nastiness is that the Minix bootloader - which would be running in supervisor mode - would have to change its own page map while it is running. This can be a little mind-bending when you need to change the map of the page on which you're currently executing code.
Still, I'll probably end up doing that. Right now, Magic-1 boots to a ROM-based boot monitor that has the ability to look on the hard drive for saved images of my current OS/Monitor. I think what I'll do is have the Minix monitor just be another of those images. So, I could either boot to my existing OS or the Minix monitor. The Minix monitor, then, would load the Minix image and transfer control to it.
Time to jot down some random notes as I continue to look through the details of the machine dependent portion of the kernel. Note that I may be mistaken about anything here - this just represents my current guesses/understanding:
| My interrupt mechanism is a bit simpler than x86, which isn't necessarily good. Magic-1 does not have the ability to enable and disable individual interrupt request lines at the hardware level. Instead, it can only turn them all on or off. I think this is not a problem. The key bits of the x86 code are put_irq_handler(), enable_irq() and disable_irq(). The first call sets up the handler, while the second two enable and disable it. I note, though, that enable_irq() is only used immediately after put_irq_handler(). I should be just fine with replacing those three calls with two: enable_irq_handler() and disable_irq_handler(). Note also that I'm not sure I really need the hooking mechanism (which allows a chain to handlers to be associated with a single interrupt line). I'll probably only ever have a single handler per line, but for now I'll go ahead and use the chaining mechanism. | |
| Another consequence of Magic-1's inability to individually disable interrupt is that it opens up the possibility of kernel stack overflow in case of nested interrupts. In practice, though, I believe this could only reasonably happen via the real-time-clock when I'm running in single-step or slow mode. I think I can code around this in the clock handler, and to be sure I'll add a panic() test on kernel re-entry depth. I'll also need to make sure I don't globally re-enable interrupts in handlers until they've exited their own critical regions. | |
| One of my least favorite things about Minix is the way is requires physical memory to be allocated in contiguous chunks. I understand, and agree with, the rationale for doing this in the base code (i.e. - simplified for teaching purposes), but my intent for my own Minix port was to implement paging. With this in mind, I built my toolchain around an a.out format somewhat different than the ACK/Minix one. However, I think that it would be best for me to do the initial Minix port using the simplified memory scheme. I can add paging later. This means that I'm going to need to fiddle with my toolchain a bit to use a more Minix-like a.out format. Not a big deal. | |
| I'm using the same UART chips as an IBM PC, so the serial port code in rs232.c is almost exactly what I need for Magic-1. However, I am using memory-mapped IO rather than x86's port IO. My inclination at the moment is to simply define some preprocessor macros for inp() and outp() than turn into memory dereferences. By doing this, I could use the rs232.c code virtually intact. It is a bit messy, though, and could mask a spurious use of port IO. Might change my mind and just do a cleaner rewrite. | |
| There's a comment in the kernel assembly code (mpx386.s) that mentions an assembly code file called "rs2.s" that I don't seem to have. Just a note to myself to make sure I didn't delete it by mistake. I suspect it may have existed in an earlier Minix release. Check this out. |
I spent a lot of yesterday working on the Minix port - things are moving along. The basic Minix kernel image consists of three concatenated executables files: the kernel proper, the memory manager and the file system. The memory manager and the file system are user-mode programs, and are relatively machine independent. Both of these are now fully built and linked. I'm also completely compiling the C portion of the kernel - but still have a quite a bit of work to go on it.
In the past, Minix has run on several different platforms - but quite a lot of x86-specific code has found its way into what probably was at one time platform independent code. It's not too bad, though.
From here, the biggest thing I have to do is work out the details of my trap/interrupt mechanism. I've already done this in the past - and in fact my current OS/Monitor uses a scheme based on my understanding of Minix. Still, it's complex enough (and been long enough) that I'll need to take a step back and work it all out again.
I also need to firm up the booting mechanism. I'd like to be able to boot a Minix image from my current OS, but there are some tricky complications dealing with remapping the supervisor mode page table while in supervisor mode.
This is a holiday weekend, and it's a bit foggy/rainy outside so perhaps I'll find some more time to work on this today and tommorow. I'm anxious to boot to a "Hello World" stripped down kernel. I don't think I'm too far away from that.
Now that I've recovered from showing Magic-1 at last weekend's Maker Faire, I've started picking up the Minix port. Not much new progress - mostly just remembering where I left things. The current state of the port is as follows:
| I have a working user-mode program to partition my hard drive into a Magic-1 partition (for the current monitor/OS) and a Minix partition with an empty Minix file system. | |||||||||||||||||||||||||||||||||||||||||||||||||
| I have the Minix boot loader/monitor running in user mode under my current OS. It is capable of reading and setting environment variables, but - of course - not yet booting an image. | |||||||||||||||||||||||||||||||||||||||||||||||||
| I've created a baseline Minix source code base, using the 2.0.4 16-bit source with all available patches (from A. Woodhull's site). I decided to start with a fresh source base, rather than the hacked-up source base that I've been using for my libc.a. | |||||||||||||||||||||||||||||||||||||||||||||||||
I've made a couple of passes through the source code to identify the
machine dependent portions. A rough outline of the needed source
changes follows:
|
I'm going to be working on several paths in parallel. One is the construction of a Magic-1 functional simulator to speed bringup. Another is to set up the cross build environment for Minix (separate from my current cross build environment for my hacky monitor/OS). This will involve doing a kernel cross build. Along the way, I'll also likely enhance my current OS to test out needed kernel features. In particular, I think I'd better get setjmp/longjmp working.
This is all going to take a while.
After a bit of a break, I'm working on the Minix port again. I've decided that I'll do most of the bringup and debugging on a Magic-1 simulator. Blinky lights and front panel switches are fun, but debugging will be vastly easier in simulator. Although I wrote a low-level simulator a few years ago to validate the hardware design and microcode, my plan is to write a new functional simulator for the Minix port. I envision a fairly traditional design, with support for checkpoints and reverse execution.
In preparation for this, I reworked my home development environment. I'm using an Ubuntu 7.04 Linux virtual machine running inside of VMWare workstation for my primary development, with a cvs server running on a separate native Linux box. I've written quite a few simulators over the years, so I expect this to go fairly quickly (assuming I can find the time...).
Found a few hours and made some good progress today. The Minix boot monitor is up and running - except for the actual booting part. Previously I hacked up parts of the Minix makefs program to create a Minix file system on a Minix partition on my hard drive. The boot monitor is now capable of reading & setting environment variables, as well as searching for boot images on the new file system. For the moment I'm running it as a user-mode program under my existing Monitor/OS, and I may well keep it that way for awhile. The only difficulty is that when I do need to actually have it load a boot image it is going to need to fiddle with the page table registers. This is fairly easily solved by simply adding some appropriate system calls to my current OS. Not sure which way I'll go, there.
The way I got it running was to hack up my current OS such when I opened a file named "/dev/c0d0" it recognized this as the entire Master IDE drive (and /dev/c0d1 as the slave). This allowed the Minix boot monitor complete access to the drive similar to the way it would normally expect PC BIOS to operate. Quick and simple within the existing file system framework.
The biggest change I made was to simplify the boot process. Minix on the PC has to work within the standard BIOS boot environment, which is a bit tricky. Most of the work I did was removing unnecessary code (or more precisely, figuring out which code was unnecessary). Eventually, I'll move the boot monitor into ROM, and expect to skip the initial bootstrap loader.
Anyway, I'm not too far away from beginning to load real Minix kernel images. My first cut will be just to get the load process complete enough to return a "Hello World" message with whatever I hack up for kputc(). Of course, given how busy things are at home and work (with holidays coming up), it may be a while before I find another block of time to play with.
It's time to start a new diary page on the Minix port. I'll jot down notes, problems and attempted solutions here as I go. First, a recounting of the current status.
Porting Minix to Magic-1 was one of my original stretch goals, and significant parts of the design were done with an eventual port to Minix in mind. In particular, I designed the context switch mechanism to work well with Minix. The basic feature is that Magic-1 has both kernel mode and user mode stack pointer registers. When running in kernel/supervisor mode, both regular SP and the Kernel SP are updated together and kept the same. However, when running in user mode, only the regular SP is updated. In effect, this allows us to do an automatic stack switch from a user-mode to kernel stack on traps and interrupts with a trivial amount of extra circuitry.
My plan is to use Minix 2.0.4 as the source to port. A new version of Minix, 3.0, has recently been released and I had hoped to use it. However, I have concerns about the ability of 3.0 to operate in the limited memory footprint that Magic-1 will support. Also, some of the major changes that 3.0 will support are of little value to Magic-1. Still, once I get 2.0.4 running I may change my mind and try a 3.0 port.
Throughout the development of the current monitor/OS I've been using code from Minix's libc. However, my current monitor/OS is pretty much a monolithic hack job. My file system is as simple as I could make it. There are a fixed number of fixed-size contiguous slots on the hard drive for files. For executables, I first load them into memory and then flush them to similarly fixed slots on the hard drive. I did experiment with a few more elegant mechanisms, though. Programs are executed in the current monitor/OS by creating a page table for the process and then turning it loose. Pages are faulted in on demand as needed. I've also have fork working via creating a new page table and using copy on write for data pages.
For the last six months or so, I've been preparing for the Minix port. The first (large) step was to get my toolchain in order. Although I've had the lcc C compiler and a custom Magic-1 assembler working for some time now, they weren't in very good shape. First, my assembler could only generate absolute executables - I had no linker. So, to compile a big program like Original Adventure, I had to include all source files into a single one. For include files, this also meant that they had to include not only the declarations, but their code bodies as well.
Things are much better now. I did a significant rewrite of the assembler to support relocatable object files. I also wrote a linker from scratch and ported nm, size, ranlib, ar and lorder. I ended up choosing a slightly modified version of early BSD's a.out format. Additionally, I added both float and double support to my lcc retargeting. All current Magic-1 programs are now built from relocatable object files.
As part of the process of getting the toolchain in order, I've been compiling the Minix source base. For the most part, I'm not running the resultant code, but just pushing it through my compiler, assembler and linker to flush out obvious problems. At this point, it's looking pretty solid.
So, I think I can declare the preliminaries complete. The Minix port begin in earnest now.
As a first step, I'm planning to getting the Minix loader/monitor working. However, this presents a bit of a challenge. The Minix loader has built-in knowledge of the Minix file system, which it uses to locate and find an OS image. However, even if I got that code working, I have no existing Minix file system images for it to load from. There are a number of ways I could approach this problem, including mounting my Magic-1 hard drive on a PC and creating a Minix file system using an existing utility. Instead, though, I think I'm going to teach my current monitor/OS about the Minix file system.
My next project will be to add code to partition my hard drive into a Magic-1 partition (that supports my current brain-dead fixed file scheme) and a Minix partition to cover the rest of the drive. Second will be to add code to create a Minix file system on the Minix partition, and finally to accept a file image in Hex format over the serial port and then write it to the file system.
Once these things are done, I can work towards getting the Minix loader to load and launch an OS image. Also, while all of these things are happening, I want to keep the current system operating.
 By
itself, that isn't particularly interesting, but a few years ago my brother Jim
Buzbee (and a few other folks) discovered a back door into the device and were
eventually able to login to the device (which runs a streamlined version of
Linux) and take control. From there, a large and active developer
community arose and now there are multiple distribution of Linux that can be
flashed onto the tiny box. You can turn it into a file server, media
server - just about anything.
By
itself, that isn't particularly interesting, but a few years ago my brother Jim
Buzbee (and a few other folks) discovered a back door into the device and were
eventually able to login to the device (which runs a streamlined version of
Linux) and take control. From there, a large and active developer
community arose and now there are multiple distribution of Linux that can be
flashed onto the tiny box. You can turn it into a file server, media
server - just about anything.